
In the first post in this series I dug into some of the implications of the widespread use of LLMs for software development. I didn’t try to justify their usage–by this point in time they are table stakes. My personal experience matches that of most folks who are using LLMs day-to-day: A year ago, they were only good for small toy apps, but by now they have improved enough that I use them for all of my development, mostly successfully.
So how did they improve so rapidly? It’s interesting to see what’s changed over the past couple of years leading to this increased ability to generate good software. But nothing is free, so what are the costs? Despite their improvements, LLMs remain imperfect. And, as I’ll show, their improvements come with increased costs in a number of dimensions.
Not Algorithm, Not Scale
Traditionally with software we expect that major improvements are the result of fundamental code changes. While LLMs have been tweaked over time, the basic algorithm remains the same. In the past couple of years in particular, core code changes do not appear to have been a major factor in their software engineering gains.
For many years, increased scale in both hardware and data dramatically improved LLM performance. Traditional software runs faster on bigger hardware, but it doesn’t get smarter. LLMs were different – larger models trained on more data genuinely became more capable, not just faster. That dynamic seems to have faded. The major labs have quietly stopped publishing parameter counts and training compute figures, so it is hard to be sure of the impact. Scaling almost certainly continues, but it does not appear to be as aggressively driving recent improvements.
It’s not just scale information that’s disappeared. Anthropic, OpenAI, and Google used to openly publish detailed technical papers and boast about their model sizes and training volumes. Now they’re more guarded. Information leaks out through system cards, technical reports, and occasional research papers, but it’s partial and requires interpretation. A lab might announce improved reasoning without explaining what that means technically, or claim support for million-token context windows without disclosing how accuracy degrades as that window fills. With that caveat noted, here are the improvements I found that seem most significant.
RLVR: Reinforcement Learning with Verifiable Rewards
A year ago, asking an LLM to generate code was a bit of a coin flip. The LLM would quickly produce code, with the assurance that it was exactly what I requested. Upon viewing or running it I might discover that it was garbage. This wasn’t entirely surprising given how these models were trained. The dominant approach was RLHF, Reinforcement Learning from Human Feedback, where human raters evaluated model outputs and those preferences guided training. The problem is that while humans are reasonably good at judging whether an explanation looks correct, they can’t reliably run code in their heads. So models got very good at producing code that looked OK, but might not actually work.
For many cases, labs now use RLVR, Reinforcement Learning with Verifiable Rewards, to replace human judgment with a test runner. The model generates code, the tests run, and the result is binary: pass or fail. With this approach there’s no ambiguity, no “this looks reasonable.” The entire system can be extensively trained with code that is run through a compiler, scanned, and tested without any human involvement. This is a far faster, cheaper, and effective way to train an LLM to produce correct code.
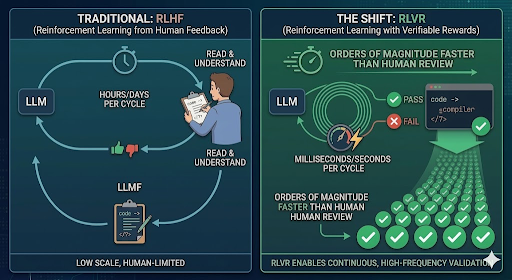
figure 1: RLHF vs RLVR
OpenAI’s o1 was among the first public disclosures of this approach applied at scale to coding, using competitive programming test cases as the reward signal. Codex-1 extended it to real-world coding tasks. What’s still opaque are the specifics: none of the labs publish the mix of problems used, how they filter for contamination, or the ratio of synthetic to human-written test cases. The technique is now mainstream across all the major labs; the details of how each applies it remain proprietary.
Tools and Training
Modern software development depends on a vast ecosystem of tools spanning the entire lifecycle: design tools, editors and IDEs, compilers, version control systems, package managers, test runners, debuggers, static analyzers, and deployment pipelines. Long before LLMs arrived, developers had accumulated decades of recorded interactions with these tools across GitHub, Stack Overflow, documentation, and shell histories.
The same principle – train against verifiable outcomes rather than human preferences – turns out to be exactly what was needed to help LLMs use tools reliably. Earlier agent systems bolted tools on externally and hoped the models would figure out how to use them. They often didn’t, failing in ways that were hard to predict and harder to debug. Modern LLMs train on pre-existing tool usage in some cases, and add specific training for other tools, in some cases using the same RLVR techniques previously described.
Before getting into how that works, it’s worth clarifying what counts as a “tool” for an LLM. There are essentially three tiers.
Command Line Interface (CLI)
The first is the command line interface. This might seem like a strange place to start given that CLIs are decades-old technology, but that history is actually the point. There is an enormous amount of training data showing humans using CLIs effectively, and the outcomes are deterministic. A command either works or it doesn’t, which makes training straightforward. The result is something of a CLI renaissance: an ancient interface turns out to be one of the most powerful ways to work with LLMs today, precisely because the models have been so thoroughly trained on them.
Built-in Tools
The second tier is built-in tools, purpose-built for things the CLI doesn’t handle well. Anthropic’s str_replace editor, introduced in October 2024, is a good example. Rather than passing file editing commands as external tool definitions, Anthropic trained five specific commands directly into the model: view, create, str_replace, insert, and undo_edit. Because the model was trained on these commands with reward signals tied to whether the edits actually worked, it learned to use them far more reliably than most externally wrapped tools. The SWE-bench Verified scores tell that story: GPT-4 with a basic retrieval setup scored 1.96% in October 2023. By October 2024, Claude 3.5 Sonnet using the str_replace harness reached 49%. By late 2025, scores were pushing past 77%. That trajectory reflects cumulative improvements across multiple factors, but better tool training is key to it.
It’s not clear if the powerful set of commands used by Claude Code are trained via RLVR, but this would be consistent, so is what some suspect.
Tool training doesn’t stop at success cases. Recent research has shown that explicitly training a model to diagnose a failed tool call and produce a corrected follow-up – rather than just prompting it to “try again” – substantially improves reliability in multi-turn interactions. Left to its own devices, a model that fails a tool call tends to repeat the same mistake. Trained on the repair process directly, it learns to recover.
MCPs
The third tier is MCP, the Model Context Protocol, which Anthropic introduced in late 2024 to extend LLMs with a wide range of capabilities. The general idea is that MCP interfaces are much simpler than APIs and self-documented in such a way that LLMs are more likely to successfully use the services they expose. This differs from the other types of tools as it greatly expands the capabilities of LLMs, but most MCPs are not “trained-in” to them.
There are thousands of MCPs available now, connecting LLMs with servers, services, and applications that traditionally required APIs, CLIs, or manual interaction. This standard has since been adopted by many LLM providers. The evolving best practice is to use CLIs for relatively simple operations, such as file system and git calls, relying on the LLM’s understanding of these common CLIs, and save MCP invocations for more complex tooling not available through CLIs.
The rapid proliferation of MCPs has brought predictable problems: security issues, reliability gaps, and performance concerns. And despite being more LLM-friendly than APIs, MCPs still add meaningful complexity compared to CLIs.
Large Context Windows
The context window is everything the model can “see” at any given moment: your current conversation, any files or documents you’ve included, the system prompt that configures the model’s behavior, and the model’s own prior responses in the session. It’s a fixed-size working memory, measured in tokens.
Context windows grew from 128K tokens with GPT-4 Turbo in late 2023 to 1M to 10M tokens across most major models by 2025-2026. That growth is quite powerful: longer contexts mean less chopping up of large codebases, fewer mid-task resets, and more headroom for complex agentic workflows. The promise of dropping in all your material and having the model reason coherently across all of it, however, hasn’t fully arrived.
The clearest evidence comes from OpenAI’s own MRCR evaluation, released alongside GPT-4 (The chart in the section on Long Context). Accuracy falls from roughly 84% at 8K tokens to around 50% at 1M. This means that the data is all there, but the model struggles to find it. No major lab fares significantly better at the extremes, but all of them are working to improve recall.
Two distinct failure modes are worth understanding. The first is “lost in the middle,” documented in a 2023 paper by Liu et al. using needle-in-a-haystack testing. Models are better at retrieving information near the beginning or end of a long context than in the middle. The relevant material is present; the model just fails to find it reliably depending on where it sits.
The second problem is sometimes called context rot. As a long session progresses, the context window fills with earlier exchanges, explored dead-ends, and intermediate results that are no longer relevant to the current task. The context grows larger (and I’ve already shown how that is problematic) but if not carefully managed can also accumulate unrelated information, adding to the model’s confusion.
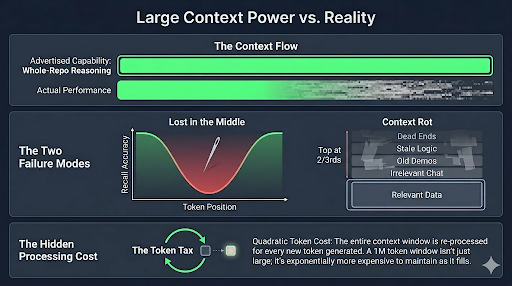
figure 2: Large Contexts. Ironically I hit context rot while generating this image and the LLM kept including irrelevant details from other conversations. I had to regenerate this in a separate, clean context.
Large context windows are genuinely useful, just not yet as much as originally advertised.
“Reasoning” Modes
The major labs now offer what they call reasoning models: OpenAI’s o-series, Anthropic’s extended thinking, Google’s Gemini thinking models. In brief: the model is trained to generate a chain of intermediate steps (Chain of Thought, which I covered in an earlier post) before producing its final answer. This uses RLVR, the same verifiable reward approach described above, so the model learns which reasoning paths usually lead to correct outcomes. The result is a hidden thinking trace that the user typically doesn’t see, followed by a response that reflects whatever the model worked through.
This can produce genuine improvements on multi-step problems, particularly in code and mathematics. Don’t get fooled by the ‘reasoning’ and ‘thinking’ in their product names. That’s marketing hype to make them seem more impressive. The process is still token prediction — the model is not reasoning in any sense that would be recognizable to a logician or a cognitive scientist.
In addition, Anthropic’s own system card for Claude 3.7 states that its chains of thought are not faithful or complete representations of what the model is doing internally. The visible thinking trace is an output, not a window into the model’s actual process.
There are costs to this approach. A chain of thought can be a pretty long internal ‘discussion’ the LLM has with itself as it builds logical context towards its answer. This can take up quite a few tokens which takes time and costs the user money. This is the first place where the improvements described in this post start to translate directly into higher costs, a theme I’ll return to.
Agentic Patterns
Given the improvements in accuracy and reliability LLMs have reached a stage where they can reasonably pursue multi-step tasks autonomously, check their own results, and keep going. Terms are evolving in this fast-moving world, but this is what I mean by agentic coding: One or more LLMs working independently or together to achieve a longer-term goal. Chatbots that wait around to answer user questions are agents, but not my focus here.

Ralph Wiggum
In early 2026, Geoffrey Huntley popularized a pattern he named the Ralph Wiggum loop, after the Simpsons character whose defining trait is stubborn persistence. The idea is straightforward: rather than working with an LLM in an increasingly large context to create and fix the code, you run it in a loop, feeding each iteration’s output (errors and all) back as the next iteration’s input, until the result passes a defined test. Each iteration is spawned in a fresh context window. The agent reads the spec and relevant state from disk, makes one attempt to create the correct code, commits it, and exits. This directly addresses context rot by preventing the accumulation of stale intermediate state.
The tradeoff is that memory now lives on disk (or github) rather than in context, which means the model must re-orient itself from file state at the start of each iteration. If the original specification isn’t quite right or the model can’t reliably construct a useful state from the last stopping point it may loop forever without converging. Time will tell if this technique fades away or gains more traction, but it is an interesting approach to leveraging the power of LLMs.
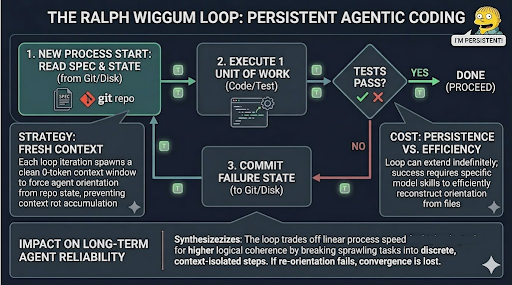
figure 3: The Ralph Wiggum Loop. I left the error ‘Synthesizezizes” in the visual, because that seems like something Ralph would say.
Teams of Specialized Agents
A more sophisticated approach is multi-agent systems, where different models (or different instances of the same model) take on distinct roles. The reason this works better than assigning everything to one agent is twofold.
The first is leveraging different system prompts to pull the model into different regions of its training. A prompt framing the model as a pessimistic security auditor surfaces behaviors that a general-purpose developer prompt systematically underweights, partly because RLHF training biases models toward being helpful and agreeable. Specialization isn’t just about reducing scope — it’s about deliberately activating parts of the model’s capability that a generalist framing tends to suppress.
The second is context focus: a model given a narrow, well-defined role with a context window populated only with what’s relevant to that role produces more reliable output than the same model handed a sprawling task with mixed concerns.
In practice, the roles emerging in real workflows tend to mirror how engineering teams already divide responsibility.
- A coder agent takes a spec or issue and implements it, producing code and tests.
- A reviewer agent reads the diff and checks for logic errors, style violations, and test coverage gaps.
- A QA agent runs the test suite, analyzes failures, and generates regression cases.
- A security agent scans the output for common vulnerability patterns.
- A planning agent (in more structured workflows) breaks a high-level requirement into discrete, implementable tasks before any code is written.
Matt Pocock, a TypeScript educator, recently open-sourced his personal agent skill configurations, which include concrete implementations of several of these patterns — TDD workflows, systematic diagnosis loops, and spec-to-issue decomposition. The repo went viral in the TypeScript community and has broader relevance as a worked example of what structured agentic workflows look like in practice.
Adoption and Reliability of Agentic Patterns
Agents for coding are a new paradigm that wasn’t feasible a couple years ago, so there aren’t many statistics on the uptake, reliability, and trustworthiness of agentic techniques for software development. Anthropic reports that 79% of conversations on Claude Code were identified as automation (agentic), but this is just one, early data point that doesn’t talk about successes or challenges with this technique.
Narrower focus and reduced context help LLMs succeed, but when chaining strings of LLMs together a single failure (in this case failure to properly perform its task) can lead to hidden or cascading issues, particularly if human oversight is lax.
What This Costs
The improvements described throughout this post all add value, as they have dramatically improved the programming capabilities of LLMs. But most of these improvements are achieved by throwing more tokens at the problem.
Reasoning models build long internal chains before producing a response. Large context windows mean the full context is re-processed with every new token generated. Agentic workflows replace a single human prompt with potentially thousands of model-generated queries running in sequence. A task that consumed a handful of tokens two years ago can easily consume orders of magnitude more today. Individually, each improvement is worth it, but overall, the direct cost of tokens is becoming a challenge.
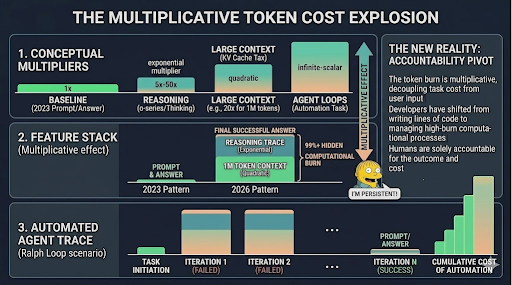
figure 4: Token costs increase
Token costs show up on the monthly bill so are readily noticed. The externalities of this arms race are large enough to attract attention. Millions of developers, running millions of tasks, and chewing through vast quantities of tokens has contributed to an explosion in datacenter growth. And those datacenters require electricity, cooling, and water in quantities that are drawing scrutiny from regulators, communities, and power grid operators. How this will be resolved is playing out in communities across the world.
For those relying on these AI to develop software, the costs are less visible but just as real. Tooling shifts every few weeks. Models are updated without notice. Anthropic has changed its pricing and contract terms multiple times in the past year. Google’s Gemini offers a wealth of features but with challenging stability (this is putting it nicely–my paid Gemini often hangs on me mid-response). AI products change and ship before they are reliable, and paying customers absorb the quality assurance work that the labs have not finished.
The pace also creates a more fundamental tension. When a model can generate hundreds of lines of code in seconds, the pressure to keep moving is strong. Speed amplifies the oversight problem rather than solving it. The faster the output arrives, the harder it becomes to maintain the kind of careful review that the LLM’s error rate demands. In the end, humans must retain accountability for the software because the AIs are incapable of doing so. By many accounts there is more pressure on software developers than ever.
The effects on the software profession as a whole are starting to become apparent. The assumption that AIs are so good that they can substitute for junior engineers has led to reductions in entry-level hiring that are suggested by some data and reports by folks in the industry. Junior engineers are the mechanism through which the industry trains its next generation of senior engineers. Hollowing out that pipeline will have long-term consequences as fewer people will progress from junior to senior, gaining all the knowledge about languages, systems, processes, techniques, and foibles.
There is also no settled answer on how to staff and structure engineering teams in this environment. More engineers or more AI infrastructure? Retrain or replace? Require or cap usage of LLMs? These decisions are being made under pressure, with incomplete information, at every level of the industry simultaneously.
Where Does This Leave Us
At the end of Post 1 I landed on four conclusions:
- AI tools have crossed a threshold of speed and code quality that creates real competitive pressure.
- The technology has not stabilized and the rate of change is genuinely difficult to keep up with.
- Human expertise and oversight remain essential. AI is a powerful implementation engine, but design, architecture, and accountability are still human responsibilities.
- Humans are more of a bottleneck than ever, putting more pressure on us.
This post provides the backstory on how we arrived here. A rapid series of improvements has produced a kind of synergy, dramatically improving the quality of code that LLMs can produce. That, in turn, has accelerated the software development lifecycle to a frenetic pace.
Nobody has figured out the equilibrium yet. Not the labs, not the teams, not the profession. The fundamental changes to this ecosystem are occurring so rapidly that it isn’t possible to keep up with all of them, or to understand their full costs in real time. The industry is making significant decisions, about hiring, team structure, and tooling, under pressure and with incomplete information. That is challenging and unlikely to change soon.
Two things came to me while putting this together that I keep coming back to.
The first is that none of this changes what good software development actually looks like. Assemble teams of smart, motivated people. Give them clear direction. Make sure they have the tools and support they need. Maintain high standards and carefully verify what you produce. AI accelerates everything, including mistakes, which makes the foundation more important, not less.
The second is more personal. I’ve enjoyed programming for years. Working with this new paradigm clarified something though: what I really care about now is making great products that people love. I don’t have to write every line of code to feel good about what I produce.