
Welcome to the fourth and final post explaining my experiments digging into the internals of LLMs to see if I can detect signals that would indicate hallucinations. In the first post I laid out my motivation and the initial test. In the second post I dug deeper into the statistics I used when looking for changes between true and false statements. In the third post I spent time discussing the challenges involved with using an LLM as a research partner before describing the next set of experiments I ran in an attempt to tease out useful signals.
With this final post I’ll talk about some of the last directions I pursued. In reality, I tried many more test variations than I describe in all of these posts. It was fun, interesting, and relatively easy (given my test harness) to run various experiments. But I had to decide which were most representative of my overall approach and best illustrated the results I obtained when putting together these articles.
I’ll wrap up with a discussion on some of the really interesting industry work going on in this area, and what researchers have and have not found.
Organic Failures
My previous experiments featuring plausible pairs, forced completions, continuation cascades all tried to force model uncertainty. The model was either processing statements I had selected (some true, some false) or being artificially manipulated to output wrong tokens. In none of these cases was the model actually struggling to generate correct information because it lacked the ability to do so. The results were mixed.
This led to a shift in thinking: instead of trying to detect when the model processes false statements, I wanted to find tasks where the model would genuinely fail. Tasks where it would attempt something beyond its capabilities and the internal states would reveal that struggle.
Math Problem Dataset Design
GPT-2 was trained primarily on text, not arithmetic. It can handle simple math through memorization of common calculations, but large number multiplication requires actual computation, which is something transformers don’t naturally do well. The architecture processes sequences of tokens, not numerical operations.
I knew a test set based on math would:
- Be objectively verifiable: There is no ambiguity about correctness (unlike “longest river” debates)
- Force computational failure: GPT-2 wasn’t trained for arithmetic computation
- Not have confounding factors: Problems can’t be explained away by training data frequency or semantic plausibility
So I came up with a dataset consisting of 19 six digit by six digit multiplication problems to test with. And, of course, I hand-verified the results, as I could not count on the LLM assistant to tell me what they should be!
An Entropy Threshold
When I analyzed GPT-2 Medium’s internal states while attempting these math problems, a pattern emerged that hadn’t appeared in the plausible pairs testing. The model showed consistently elevated entropy when attempting arithmetic it couldn’t perform. This was different from the plausible false pairs, which showed entropy in the normal range (~0.75) regardless of whether the statement was true or false.
When the model lacks the computational ability to generate the correct answer, entropy seems to increase. The attention becomes less focused, more diffuse, as if the model is “searching” across many possible patterns without finding a coherent solution.
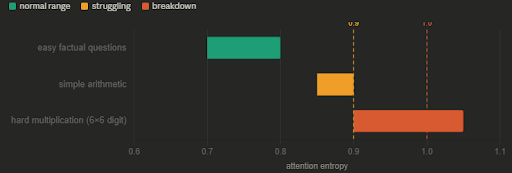
Entropy values above 1.0 seemed to indicate complete breakdown. Below 0.9 the model was functioning normally. The range 0.9-1.0 represented struggling but still attempting to generate something.
Comparing Genuine vs Artificial Failure
In my early tests, the model was processing plausible-but-false statements that existed in its training distribution. It handled them fluently even though they were factually wrong. In the second case, the model was attempting a task (large arithmetic) it fundamentally cannot perform. That genuine inability showed up as elevated entropy.
This suggested that entropy might detect computational failure rather than general hallucination. When the model can’t do something, entropy increases.
Establishing Baselines
To verify this wasn’t just noise, I wanted to test control comparisons like: “What color is the sky?”, “What do cows produce”, and “Are dogs animals?” These are questions GPT-2 should handle correctly through simple pattern matching from training data.
This established a baseline: when the model knows the answer through training, entropy remains moderate and stable.
- Accuracy: High (most answered correctly)
- Entropy: ~0.7-0.8 (below the math problem range)
Ramping the tests up a bit, I picked questions that fall between trivial questions and impossible large multiplication: 2 × 3 = ? 5 × 4 = ? 10 × 2 = ?
- Accuracy: Mixed (some correct, some wrong)
- Entropy: ~0.85-0.90 (intermediate range)
This suggested a gradient: as task difficulty increases, entropy rises. Easy questions show low entropy, moderate difficulty shows intermediate entropy, impossible tasks show high entropy.
Testing on Factual Questions
For the next tests I tried to turn up the complexity just a bit more, to see if this trend continued and the entropy signals I saw generalized beyond arithmetic to factual knowledge. My next set of questions were fairly simple, and non-mathematical:
- “Who invented the telephone?” (expected: Bell)
- “Who was the first US president?” (expected: Washington)
- “What did Einstein win the Nobel Prize for?” (expected: photoelectric effect)
The resulting pattern was less clear than with math. Easy historical facts (Washington as first president) showed low entropy. Harder questions (Einstein’s Nobel Prize reason) showed elevated entropy, particularly when the model generated incorrect answers. But the signal was weaker and less consistent than with computational tasks.
Entropy might detect computational failure more reliably than knowledge gaps. Math requires actual computation that the architecture can’t perform. Historical facts might exist in training data but be weak or contradictory, creating a different kind of uncertainty.
By this point I had tried many different tests, and detected inconsistent signals. I wanted to run some of the more promising tests through other models to see if I was in fact seeing useful patterns, or just noise in GPT-2 Medium’s internals.
Testing More Capable Models
I chose two models I could easily run, and replicated a number of the scenarios.
GPT-2 Large (774M parameters): Despite having roughly double the parameters of Medium, Large showed fundamentally different patterns and performed poorly on basic tasks. On hard math problems (6×6 digit multiplication), it achieved 0/19 correct with mean entropy of 0.905—high but not discriminative. On simple questions where it managed 4/5 correct, attention entropy showed no meaningful difference between correct and incorrect answers (0.832 vs 0.849, p=0.71). Instead, different signals emerged: hidden variance was higher for correct answers (285 vs 266, p<0.001), and attention-to-prompt patterns differed (0.075 vs 0.068, p<0.05). These contradicted the Medium model’s patterns entirely.
Qwen2.5-0.5B (modern architecture): This recent model handled factual prompts correctly but showed consistently high entropy regardless of accuracy. “Water freezes at 0 degrees Celsius” produced accurate content with entropy 0.67-0.76 throughout. A biographical prompt about Alexander Bell generated factually correct information (dates, inventions, timeline) with entropy 0.68-0.82. The entropy remained stable across both correct factual completion and extended biographical generation, providing no discriminative signal whatsoever.
Fundamental Pattern Differences
The most significant finding was that different models exhibited fundamentally different entropy characteristics:
- GPT-2 Medium: Entropy 0.3-1.0+ range with apparent threshold around 1.0 for breakdowns
- GPT-2 Large: Entropy 0.8-0.9 range with no clear threshold; different metrics (variance, concentration) showed signals
- Qwen2.5: Entropy 0.65-0.82 range, stable regardless of content accuracy
These results did not seem to transfer between models, suggesting the patterns were model-specific rather than representing general principles of hallucination detection. What appeared possibly promising in Medium completely failed to replicate in either direction: larger GPT-2 showed different signals, while more capable Qwen showed no signals at all.
Time for a Reality Check
My summation of the investigation at this point reflects both the value and limitations of this exploratory approach.
I had a relatively quick and accessible way to investigate the internals of language model inference through attention pattern analysis. The setup was technically straightforward: extract attention weights, compute entropy and other measures, compare patterns across different types of content. This provided an empirical window into model processing that would have been impossible with black-box systems.
The results showed tantalizing but unclear indicators that different types of processing were represented in measurably different ways internally. GPT-2 Medium did show entropy spikes during certain failures, structural differences between true and false statement processing, and patterns that seemed to correlate with accuracy. However, nothing conclusive emerged from any single model, and the limited results did not transfer to other architectures or scales.
I chose to wrap up my experiments at this time. As interesting as this work had been, I had spent quite a bit of effort on it, and did not feel that I had strong results to follow up on.
Industry Research
My experiments fall into the broader category of mechanistic interpretability: the attempt to understand what is actually happening inside a model during inference, rather than just observing its outputs. This is an active and growing research area, and the approaches being taken by research teams are considerably more sophisticated than what I was doing. Understanding why my approach hit a wall requires a quick look at what the research has found.
Some of the more sophisticated investigations I had encountered in recent mechanistic interpretability research provide insight into the fundamental challenges I was encountering.
Internal model representations are polysemantic—individual neurons and attention patterns respond to multiple, unrelated concepts simultaneously. A classic example: the same neuron might activate strongly for both “Golden Gate Bridge” (the landmark) and “golden retriever” (the dog breed) because both contain the word “golden.” This means that raw attention patterns or activation levels don’t cleanly correspond to single concepts or processing states.
The research shows that even in modern, highly capable models like Claude 3 Sonnet, superposition allows networks to represent many more concepts than they have dimensions. Features exist in combinations across multiple neurons rather than being localized to specific components, making simple analysis of individual metrics (like attention entropy) unlikely to capture complex phenomena like hallucination detection.
Linear Probes and Advanced Techniques
One more promising direction has been linear probes — lightweight classifiers trained to detect specific properties from model activation patterns across many layers, rather than from a single metric like attention entropy. Rather than assuming that raw patterns directly encode information about truthfulness, probes learn which combinations of activations correlate with the property you care about. Research teams have used this approach to visualize true and false representations in LLMs.
Sparse autoencoders take a related but different angle: instead of training a probe to detect a specific property, they attempt to decompose the entangled internal representations into more interpretable components — identifying “features” that correspond to more coherent individual concepts. Anthropic’s work on Claude 3 Sonnet showed this is possible even in large modern models, though the scale of the problem is immense.
Both approaches share something my work lacked: they use learned transformations over the raw activations rather than treating the activations as directly readable. That distinction matters a great deal given what we know about polysemanticity.
The Knowledge Uncertainty Question
There is still active debate about a more fundamental question: does a model have any internal representation of its own uncertainty about what it is generating, or does it simply produce the highest probability continuation regardless of whether that continuation is accurate?
Some research suggests models do maintain internal states that correlate with truthfulness — that the signal is in there somewhere, just not accessible through simple metrics. Other work points to the opposite conclusion: that generation is fundamentally a pattern-matching process with no explicit truth evaluation happening. The model processes “Einstein discovered penicillin” and “Einstein discovered relativity” through the same mechanism, selecting tokens based on learned statistical associations without any separate verification step.
My experiments didn’t resolve this question, but they did illustrate it concretely. The plausible false pairs showed no entropy signal at all. In those tests the model was equally fluent and confident whether the statement was true or false. That behavior is consistent with a model that has no meaningful internal uncertainty signal for factual accuracy, at least not one visible at the attention layer.
H-Neurons
One recent paper caught my attention as I was wrapping up this series. A team at Tsinghua University published work in late 2025 identifying what they call H-Neurons — a very small subset of neurons in the feedforward layers of LLMs whose activation patterns can predict whether the model is about to hallucinate. Less than 0.1% of total neurons, but apparently meaningful ones.
Their method uses sparse logistic regression trained on a labeled dataset of correct and incorrect question-answer pairs. The resulting classifier identifies which neurons are most predictive, then uses those neurons alone for detection. Tested across six modern models including Mistral, Gemma, and Llama variants, and across several scenarios ranging from standard QA to fabricated questions about non-existent entities, the approach showed consistent accuracy improvements of 10 or more percentage points over randomly selected neuron baselines.
The more interesting finding to me was the behavioral one. When the researchers amplified the activation of these neurons, the model became more sycophantic, more susceptible to false premises, and more willing to follow harmful instructions. This suggests H-Neurons don’t simply encode factual errors — they seem to represent a general tendency toward over-compliance, prioritizing a fluent and agreeable response over factual accuracy.
That framing connects directly to my null result on plausible pairs. The model wasn’t struggling when it processed “Bell invented the telegraph” — it was doing exactly what it was trained to do, generating a confident and fluent continuation. There was no distress signal to find because the model wasn’t in distress. The H-Neurons work suggests the relevant mechanism isn’t uncertainty at all, but something closer to a compliance disposition.
It’s worth noting this is a single paper from 2025 that has not yet been widely replicated. The results are interesting and the methodology is sound, but I’d treat it as a promising direction rather than a settled finding.
Wrap Up
This investigation provided some insight into both the promise and limitations of attention-based hallucination detection. While it did not yield a practical detection method, it demonstrated interesting aspects of how LLMs process information and highlighted the challenges inherent in mechanistic interpretability work.
The negative results are themselves informative: simple metrics extracted from model internals (unsurprisingly) do not reliably distinguish between accurate and inaccurate generation across different model architectures. Future work in this area will likely require more sophisticated techniques that account for the polysemantic and distributed nature of neural network representations.
I will continue following developments in mechanistic interpretability research with a more informed perspective on both the potential and the significant challenges involved in understanding how large language models generate and potentially detect their own hallucinations.
If you found this interesting and want to replicate or expand upon my experiments feel free to clone my github repository on this work.